
TL;DR There is none. Because this is not the right question.
What is the best software architecture pattern!?
I suppose, many developers and architects who did not taste great failures yet asked exactly this question to themselves before starting a new project or refactoring an existing one. Maybe, they researched big tech giants’ architectures, tech stacks and tried to select the best software architecture pattern with only or mostly popularity criteria.
“The thing called microservices looks shiny, even Netflix uses it. let’s do microservices.” Don’t get me wrong, this sentence and underline behavior are very normal. It’s in our nature; if something is new and popular it immediately catches our attention.
Let’s take this example, what is the best car? Is it the car that can accelerate from 0 to 100kph in 3 seconds or is it the car that is very fuel friendly but accelerates from 0 to 100kph in 30 seconds? Maybe the better question is what is the best car for me? If I try to define “me”; living in a crowded city and will use this car for a mostly home-office cycle. It will be very gratifying if I can reach the office in like 5 minutes with a Bugatti Veyron, but while I am defining “me”; said living in a crowded city so that traffic jams will be inevitable. What benefit does Bugatti bring to me while driving to the office? The time I spend traveling between home and office will be similar for each car. Besides stroke my ego, it brings many trade-offs for me like fuel consumption, very high taxes (especially in my country).
On the other side; If I were a drag racer, how can I be competitive with a car that accelerates from 0 to 100 in 30 seconds?
Let’s change the main question in this way; what is the most appropriate software architecture pattern for me(my domain)?
“There are no solutions, only tradeoffs” — Thomas Sowell
As software and technology evolve, it brings new problems and as well as new solutions. Most of you (including me) dealt with or created a big ball of mud in your career.
A Big Ball of Mud is a haphazardly structured, sprawling, sloppy, duct-tape-and-baling-wire, spaghetti-code jungle. These systems show unmistakable signs of unregulated growth and repeated expedient repair. Information is shared promiscuously among distant elements of the system, often to the point where nearly all the important information becomes global or duplicated… — Brian Foote and Joseph Yoder, Big Ball of Mud. Fourth Conference on Patterns Languages of Programs (PLoP ‘97/EuroPLoP ’97) Monticello, Illinois, September 1997
If your software lacks any understandable structure, if your pain gradually increasing with each deployment, if a simple line change in codebase has unpredictable consequences, if your software has low performance, lack of scalability, if you have to have infinite overtimes even for simple tasks, if your manager tried to recruit new people to increase productivity on the contrary productivity decreases because of new recruits drained life energy from you and other people to understand this mess and consequently, the turnover rate increased, if you have unhappy customers and if you thought of quitting job and opening a small cafe in a seaside town and gave up from this idea because of your mortgage debt…
If these sentences sound familiar, and your answers are mostly “yes”, welcome big ball of mud club and 1st rule; you should talk about the big ball of mud club and try to find a way how to fix this mess.
Software architecture patterns (even if it is not a silver bullet) is one of the patterns that help you get kicked out of the club as soon as possible. Trust me, “get kicked out” is not always a bad thing. You would not want to stay long anyway. However, I recommend that every developer and architect should enter this club once in their career for tasting desperation, pain and gaining experience about their mistakes. But try to leave early or you will get used to it.
How can software architecture patterns help to prevent this and similar messes?
Every architecture has or should have some characteristics, decisions, and governance mechanisms. As examples of characteristics; availability, continuity, scalability, reliability, maintainability, performance, deployability, extensibility, etc. and as an example of decision; only the business layer can directly talk to the persistence layer in layered architecture and restricting upper layers like the presentation layer from any interaction with the database. As a governance mechanism that helps to ensure these characteristics and decisions are not violated.
For automation of governance mechanisms, fitness functions can be used. The fitness function simply defined as a function that takes a candidate solution to the problem as input and produces as output how “fit” our how “good” the solution is with respect to the problem in consideration.
…Any mechanism that provides an objective integrity assessment of some architecture characteristic or combination of architecture characteristics. — Fundamentals of Software Architecture: An Engineering Approach
If I try to give my explanation about the architectural fitness function; function(s) that appended the ci/cd pipeline and runs on every deployment to ensure your architecture characteristics and decisions are not violated via current changes. So as a developer, you must consider architecture characteristics and decisions before committing changes.
As an example (according to the decision above); You, as a developer, must not call the database directly from the UI layer or you must ensure that selecting the algorithm with the right complexity does not negatively affect performance. In this way, If you fail to meet these requirements in your commit, fitness functions that appended pipeline prevent these changes from merging with the master branch or even worse going live. This is one of the ways to ensure architectural governance.

Leave better than you found it
… Under the broken windows theory, an ordered and clean environment, one that is maintained, sends the signal that the area is monitored and that criminal behavior is not tolerated. Conversely, a disordered environment, one that is not maintained (broken windows, graffiti, excessive litter), sends the signal that the area is not monitored and that criminal behavior has little risk of detection… — https://en.wikipedia.org/wiki/Broken_windows_theory
According to this theory, If someone imported a database layer DLL or package (based on your environment) to the presentation layer (which violates architectural decision), you wouldn’t hesitate too much to use this reference and write SQL queries in the presentation layer again. Particularly, your implementation doesn’t require any business logic. Hence, architectural governance is a must and helps to prevent these violations and cascading evolution of becoming a big ball of mud.
As I said; software and technology evolution introduces new problems and potential solutions. According to these problems and domain needs, architectural characteristics and decisions should vary and carefully analyzed for each one that you’ve encountered or likely will encounter in the future.
How to figure out architectural characteristics and decisions?

Firstly, you won’t find an architecture that compatible with every characteristic, and you should not try to find one. Let’s say your company decided to make yet another eBay. After endless hours of project planning meetings, you realized that the allocated time and budget for this project are not enough to clone eBay architecture so you left with two options. Either this mad project will be canceled or you will try to make it in a cheap and fast way. For these reasons let’s suppose, you decided to go with layered (n-tiered) architecture.
Maybe it’s the right decision for simplicity and cost perspective but as your customers, codebase, and teams grow, you will realize decided characteristics in the first place, not the right choices anymore. In different words; deployability, scalability, extensibility, reliability, and many characteristics of layered architecture no longer meet your domain needs.
Take it this way; you must deploy the whole project every line of change, which is deployability. If your database is down, likely other parts of the application, even not requiring a database will be inaccessible, in other words, any problem in a part of the application, the entire system will be affected which is a fault tolerance portion of reliability. Because of the nature of auctions, (traffic burst period of time) your architecture needs scalability and elasticity. Namely, layered architecture doesn’t meet these characteristics either primarily due to monolithic deployments and the lack of architectural modularity.
Even your customer will notice these bottlenecks by getting 503 error while trying to place the last bid on an item’s auction. I mean; you cannot easily scale just the auction component if some auction of the product was gone viral. You will have to scale your system vertically by adding more horsepower or you have to scale all systems horizontally (not easy in this case), not just the auction module. In each way, your database may be your bottleneck. Hence in either case; scaling horizontally and vertically will not cheap and sustainable.
You maybe think that if layered architecture causes these troubles, it must be a bad thing.
Of course not but this thought is not the right evaluation method. So many successful projects have used and still using this architecture. Even layered architecture considered a starting point. But does your organization have time and budget to refactor into another architecture? Or you have to maintain this architecture for ten more years? So, it’s not about bad or good things, it’s only about considering trade-offs.
You (this time as an architect) will need to learn domain needs and talk with stakeholders, business people, dbas, network administrators, developers to understand your requirements. While past experiences are helpful, you also need to think about the future as you understand from the eBay scenario above. This process needs to be recursive. Every iteration you will have a better understanding of requirements and corresponding characteristics. These characteristics will guide you while selecting appropriate architecture.
On the other issue; while deciding architectural decisions, past experiences, published best practices of selected characteristics, developer’s experiences, infrastructure characteristics will be helpful.
Partitioning
While selecting architectural characteristics and styles, you should consider partitioning which is mainly technical and domain-based.
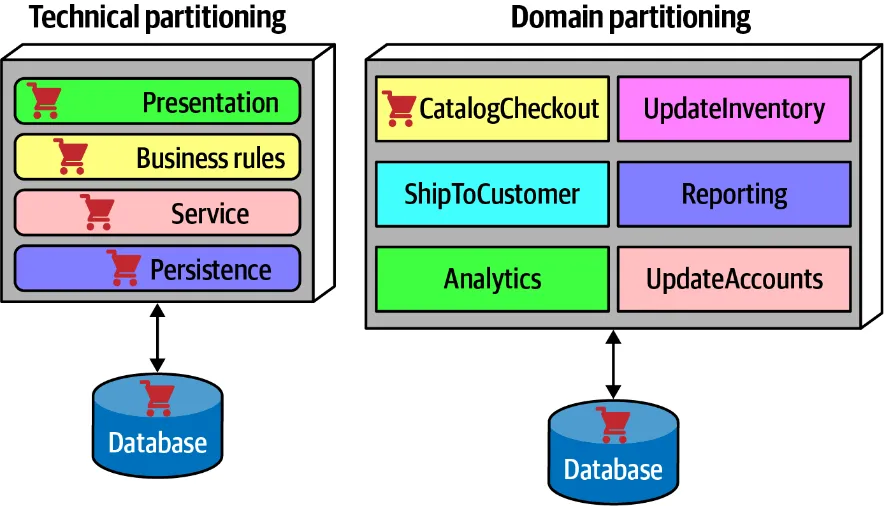
If you want to organize the components by technical capabilities, you should consider using technical partitioning. This partitioning in turn provides useful levels of decoupling. As an example; if a commit related to database, only persistence layer affected, other layers remain untouched. In addition to that, the separation enforced by technical partitioning enables developers to find certain categories of the codebase quickly, as it is organized by capabilities.
However, in the real world software system require workflows that touch every layer in the system. So your domain logic will appear in all layers. If your business rule changes, you need to make changes in all layers in this partitioning.
You should consider these advantages and trade-offs. As an example; layered architecture will be suitable for this partitioning.
If you want to organize the components by the domain you should consider using domain partitioning which is inspired by Eric Evan’s Domain-Driven Design book. Your components will be workflow or domain logic based. Each component in the domain partitioning may have subcomponents, including layers, but the top-level partitioning focuses on domains, which better reflects the kinds of changes that most often occur on projects. If your company big enough to consist of multiple development teams, you can assign each partition to a different team which is not possible via technical partitioning.
As an example; modular monolith and microservices architecture styles will be suitable for this partitioning.
Or you can use hybrid partitioning. If your domains partitioned with correct granularity, technical partitioning inside domain partitioned components is common. With this way; CatalogCheckoutdomain will be consist of a presentation, business, service, and persistence layers.
You can take references from your organization and team structure while selecting appropriate partitioning. If your organization structure is consists of many different teams and these teams have full stack professions. (I mean; if every team has its own developers, testers, business analysts, etc.) you should consider domain partitioning.
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure. — Melvin E. Conway https://en.wikipedia.org/wiki/Conway%27s_law
Monolithic or Distributed?
It depends. You should take account of different needs in the same system.
Let’s say you decided to go with domain partitioning for the example above. Your analytics module might have different characteristics from Checkout. Maybe eventual consistency is well suited for the analytics module but every transaction in the checkout module needs to be atomic and consistent. Hence, the distributed architecture may be a better fit rather than a monolithic for this case.
Rule of thumbs;
- if your architecture characteristics differ from component to component,
- if your network infrastructure well enough or be able to use cloud services,
- if you have time and money,
You may consider distributed architectures like microservices, space-based architecture, service-oriented architecture.
- if your architecture characteristics simple enough and not differ for each component,
- if your network infrastructure is consist of only some wifi routers and not willing to use the cloud,
- if you have a tight budget and time,
You should consider monolithic architecture like layered, microkernel architecture.
Never try to find the best architecture, but rather the least worst architecture.
This what you came for
Probably, before clicking this article, you hope to find at first some architecture patterns list with pros and cons and showing to best architecture you should use. I hope, you were not disappointed so far. Because I tried to explain how to figure out characteristics, decisions, patterns, and what to consider before making the final architecture style decision.
And here it is. I won’t list every mentioned architecture style in the IT world until today. These are the most used and criticized ones with brief summaries. I will divide these architecture styles in three ways; Monolithic, Distributed, and Hybrid and will try to summarize each one.
Monolithic Architectures
Layered Architecture
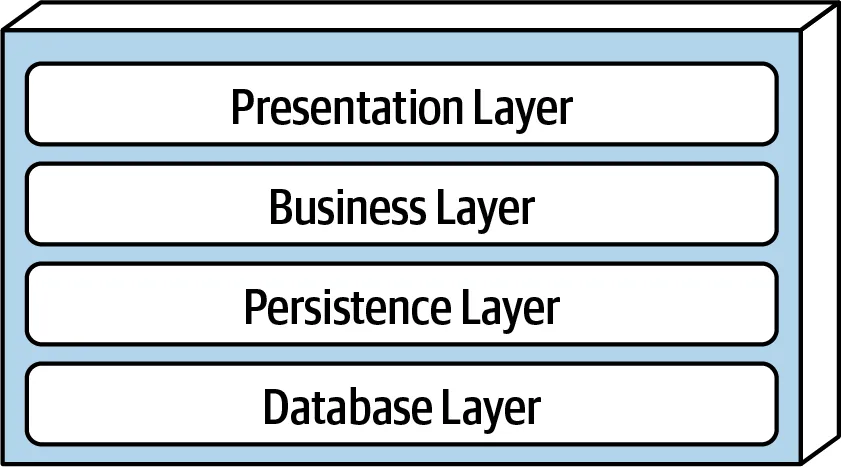
Layered architecture one of the most common architectural styles. Components within the layered architecture style are organized into logical horizontal layers, with each layer performing a specific role within the application. Most layered architectures consist of four technically partitioned layers such as; presentation, business, persistence, and database.
Presentation layer responsibility is handling all user interface and browser communication logic and pass the request to inner layers and format response according to UI.
Business layer responsibility is executing specific business rules associated with the request.
Persistence layer contains all database-related objects, ORM’s, DAO, and queries.
Database layer is where your data is stored.
All layer’s in this architecture should satisfy a particular thing. Presentation layer should not know how data is mapped to the database or Business layer should not care how data will be represented in UI.
Each layer in this architecture can be either closed or open. Closed means, the request cannot bypass a layer. As an example, if the request that saves customer data comes from the presentation layer, must go first business layer and persistence layer even business layer does not need to execute any particular business rule for that request.
Open means the opposite. A request skip particular layers, so your presentation layer skip business layer and talk directly with persistence layer.
Which one to use is decided by evaluating trade-offs. Generally, changes made in one layer should not don’t impact or affect components in other layers. Each layer should be independent of the other layers. This means if your presentation and business layer both talk to persistence directly, any changes made in the persistence layer affect both layers and producing a very tightly coupled general architecture. Your application will be very fragile and any changes will be expensive.
The layered architecture might be a good choice, especially for simple applications and websites, and as a starting point. If you are in a situation which a very tight budget and time, you should consider layered architecture.
If your choices of characteristics are simplicity and cost-effective and not deployability, elasticity, evolutionary, and scalability, you should go with this architecture.
Microkernel Architecture
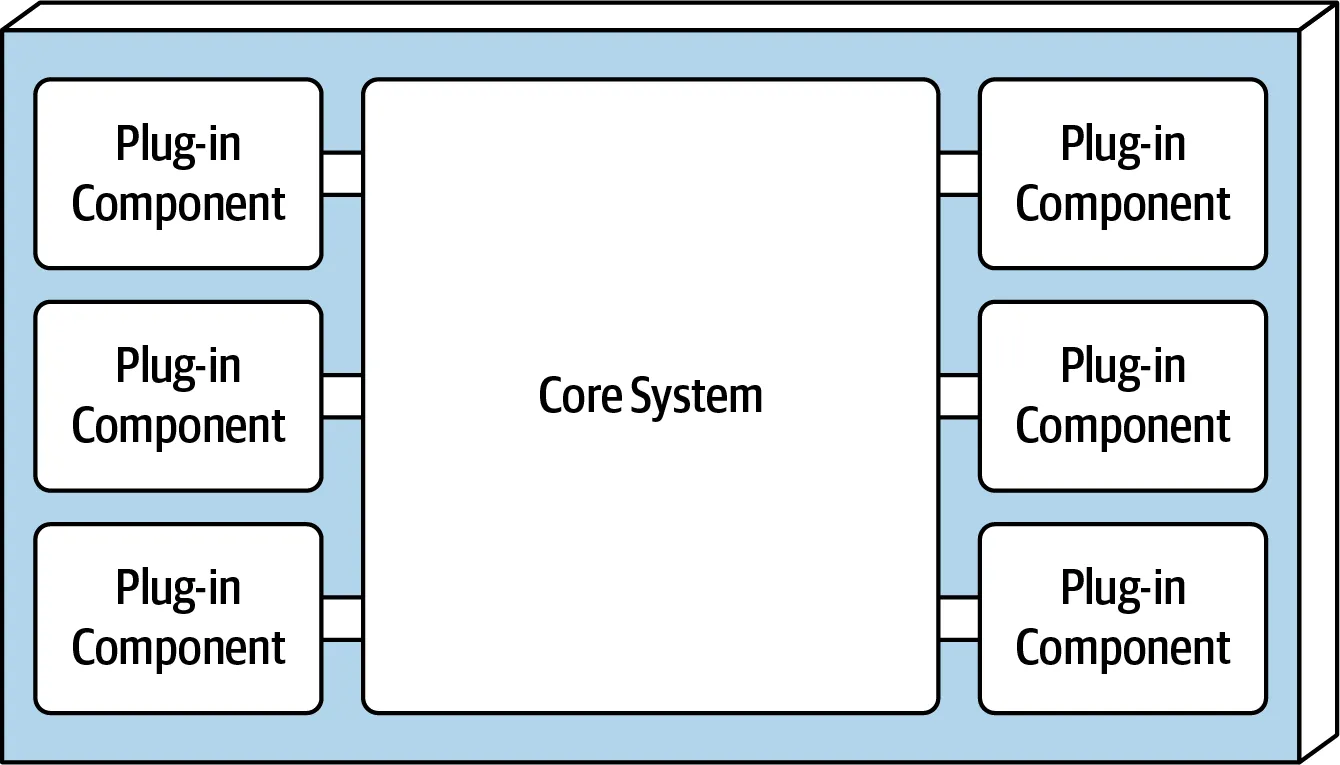
The microkernel architecture style is another monolithic architecture that supports modularity better than layered architecture. You have a core component with minimal functionality required to run the application and have multiple plug-in components that provide extra functionality.
You should consider the visual studio code as an example. After installed on your computer, it provides minimal functionality to write code. Let’s say if you want to better IntelliSense support for your programming language of choice, you would install the required plugin to get this functionality.
Plug-in components can be both compile-time and run-time dependencies. Compile-based plug-in components are much simpler and faster but require re-deploy the entire application if any of the changes made in plug-in components. Run-time components relatively more complex and slow, but they provide better flexibility. Reflections, RPC calls can be used for managing run-time components. Also, some frameworks support this functionality out of the box
The microkernel architecture good choice if you want modularity and better flexibility than layered architecture with a relatively similar budget and time constraints. The performance will be worse than layered architecture especially if you go with runtime plugin components. Scalability and elasticity characteristics not a strong suit of this architecture either.
Hybrid Architectures
Pipeline Architecture
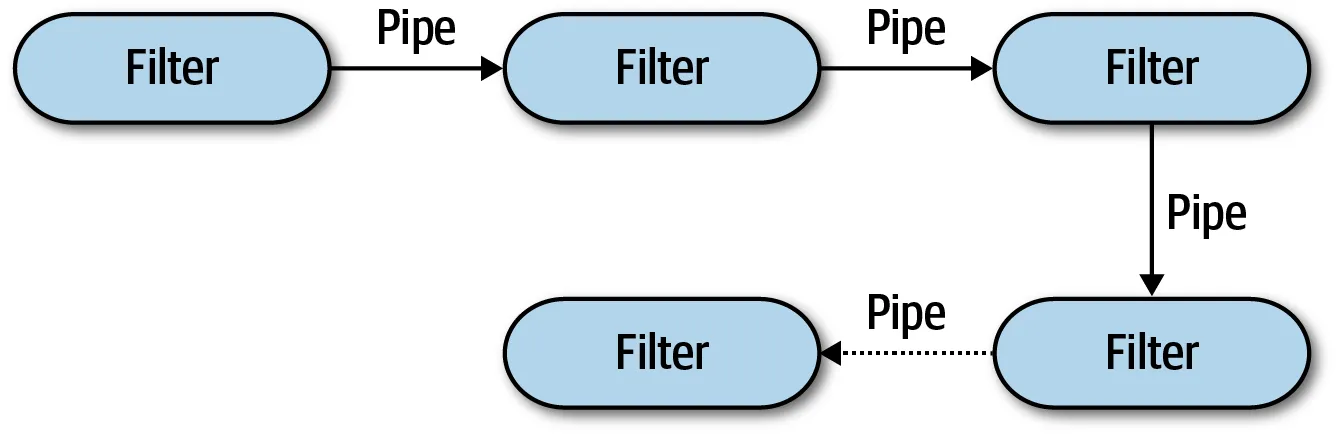
Pipeline architecture (aka. pipes and filters)can be applied to both monoliths and distributed environments.
Pipes are a channel of communication between filters. Filters can be a component, a method even a whole service that self-contained, independent from other filters, and generally stateless. Filters should perform one thing only.

Let’s say, you have a Kafka topic as a data source. The first producer filter subscribes to this topic and its only responsibility is to subscribe to Kafka then pass the message to the next filter. If you want conditional forwarding in your pipeline, your next filter may be a tester which makes some checks on data to decide where to send next. (for complex business and routing rules, you should consider implementing a state machine with the process manager. But this is not in the context of this architecture)
Another filter might be some transformer that performs a transformation on some or all of the data, then forwards it to the outbound pipe. Your last filter might be a consumer filter that saving data to the database.
Pipes are can be implemented via both in-memory methods call and distributed messaging. If you decide to go with distributed messages, you can take advantage of message brokers’ routing mechanism. Like routing keys in RabbitMQ.
Characteristics of this architecture will vary, depending on pipe implementation. If you want simplicity, testability, overall cost characteristics will be the main strength of this architecture, you should go with an in-memory way. If you prefer deployability, scalability, elasticity, and modularity you should consider asynchronous way.
Event-Driven Architecture
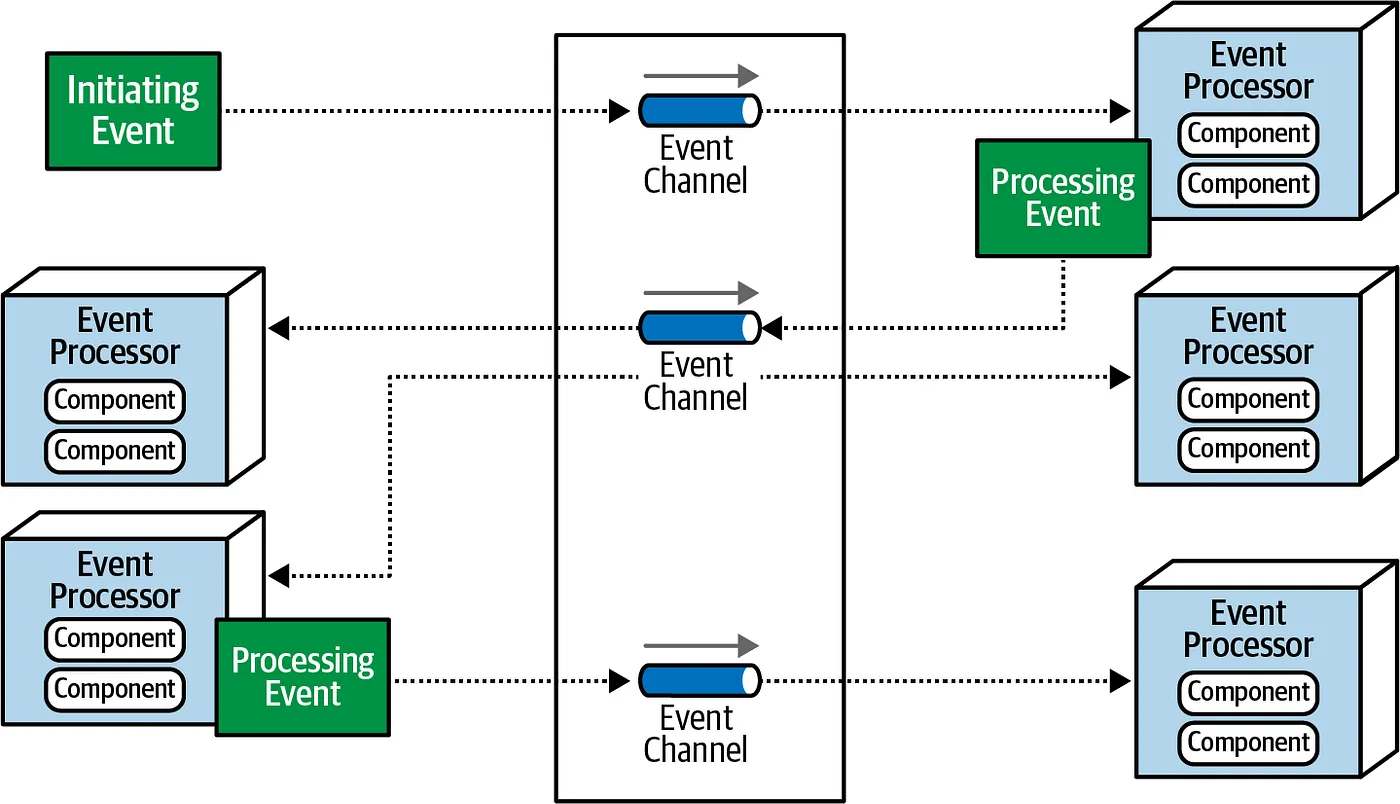
Since Event-Driven architecture is generally used in conjunction with other architectures, it would not be wrong to define it as a hybrid as well as sub-architecture style. So it can be monolith and distributed.
Event-Driven architecture as the name suggests, based on events and components in this architecture communicate with those events. If a customer places an order, the order component raises an event to notify other areas of the application. Any interested component like fulfillment subscribes to this channel for executing its own business flows.
There are commonly two types of topology which are Broker and Mediator.
Broker Topology means, there is no central mediator for event flow. The message flow is highly distributed. Components broadcast events that happened inside their workflow with fire and forget fashion. Other components which interested them can subscribe to these events for their own workflow. Commonly, an external message broker like RabbitMQ is used with this topology. While all components are highly decoupled and flow is very performant, it will be troublesome to follow the processing flow and debugging. If OrderCreatedthe message is lost, no one will ever know what happened to this order or what’s the order’s current state.
On the other side mediator topology can addresses some of the shortcomings of the broker topology described above. In this topology, there will be a central event mediator which coordinates event flow. All components subscribe to event mediator channels to wait for their tasks. Mediator checks the state of the event and sends the corresponding channel (point-to-point messaging fashion) also waiting for a response from the particular component. If the order component raises an event, unlike broadcasting event to all system, the mediator takes this event and publish to fulfillment channel. After fulfillment finishes its work, it responses back so mediator knows the fulfillment step is finished. If a message lost while sending the order to fulfillment channel, the mediator would know the order’s state and retry a particular step. Actually, the mediator topology uses commands (things that need to happen) rather than events (things that have already happened).
While implementing an Event-Driven architecture (especially distributed fashion), there are things to consider. Like error handling, losing messages, and eventual consistency. I will not go into details but you can visit the links below for more detailed information.
What do you mean by “Event-Driven”? Enterprise Integration Patterns Microservices Pattern: Sagas
The Event-Driven architecture will be a good choice if you prefer evolutionary, fault tolerance, modularity, scalability characteristics rather than simplicity, testability, and overall cost. But at the same time, these characteristics may vary according to topology, parent architecture, and environment.
Distributed Architectures
There is mainly three distributed architecture that the most used in the software systems. Space-Based Architecture,
Service-Oriented Architecture** (aka. SOA), and Microservices.
In my opinion, if you considered characteristics and decided to use a distributed architecture, Microservices should your go-to architecture style according to today’s standards. I won’t go into details of SOA and Space-Based architecture but if you want to take look into SOA and Space-Based architecture details, you can visit the links below.
Microservices
In the early days of software, open-source not a thing. In that era, you had to consider all licensing aspects such as operating system licenses, database licenses, framework licenses, while creating software. To avoid paying these license fees over and over, organizations have tried to reuse as much as possible what they have already purchased. SOA has adopted this philosophy with maximizing reuse. But reusing comes with an important trade-off which is the coupling.
After learned lessons from these trade-offs and with the increase of open source software and license problems gradually becoming a thing of the past, Microservices comes into place to address these coupling.
Microservices, as the name implies, consist of small (micro) self-contained services that do one thing, unlike coarse-grained services in SOA. This idea heavily inspired by the bounded context from domain-driven design (DDD).
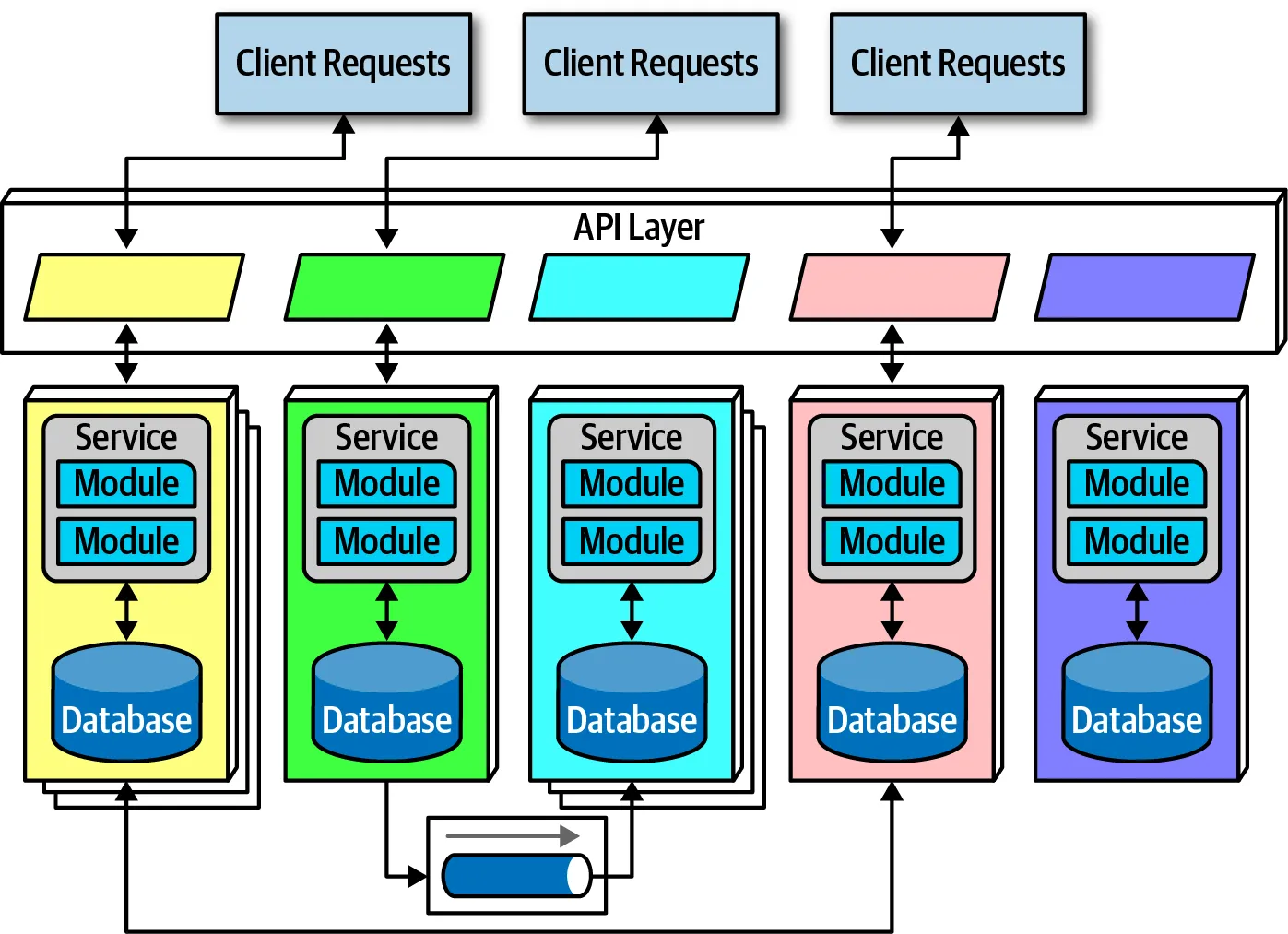
Within a bounded context, all components are coupled together with ubiquitous language to produce meaningful work. Anything outside of the bounded context should not be coupled with internal parts. (like database, other bc components, etc). In other words, Microservices are distributed domain-partitioned architecture (that I mentioned in the middle of this post) which tries to reduce coupling as much as possible.
Each service in Microservices has its own data storage. This means, data storages not sharing between services. If one data storage schema changes, only affect a particular service. Another benefit of this; you can select the appropriate database for each service. For example, if a service needs a datastore with high write throughput you can use Cassandra and in another service, you can use PostgreSQL if your data are highly relational. Even you might not use any database for stateless services. It is all up to your domain.
Containerization (like docker) is the main choice for deployments. This means no more ‘but it works on my machine’, as well as reduce infrastructure couplings.
Logging, authentication, service discovery, scaling and other cross-cutting concerns are maintained outside of bounded contexts with help of systems like Kubernetes and his friends.
The Distributed System ToolKit: Patterns for Composite Containers
All communications between microservice handling via gRPC, Rest, or Asynchronous Messaging. This means performance always worse than in-memory method calls like in monolithic architectures, but it brings so much flexibility to the table.
Each service can implement different architecture inside. If a service simple enough, you can build it as layered, or if it is more complex you can use DDD with Hexagonal architecture and combine it with Event-Driven architecture. You have this flexibility with Microservices.
It’s Not All Roses
Great flexibility and decoupling come with different problems that you might encounter like transactions. In a monolithic architecture, you have a database system to ensure ACIDity. This means; either all steps complete or no steps complete. In Microservices, the system does not have a global transaction coordinator by default.
Let’s say, you have an e-commerce website consist of three microservices OrderService, InventoryService, PaymentService. When a customer places an order, OrderService creates an order and call InventoryServicefor decreasing stock of purchased product. InventoryService successfully decreases stock and return a successful response to OrderService.
OrderServicecontinues to flow with calling PaymentServiceto charge the customer’s credit card. What happens if the customer’s credit card expired? PaymentService will not be able to charge customer credit card even stock of the purchased product has been already decreased. Should OrderService call InventoryService again to undo what has been done? Think about a real e-commerce website, there will be hundreds of services similar manner.
Saga and two-phase commit patterns should be used in such cases but the point I want to draw attention to is that not everything is rosy even in Microservices.
Patterns for distributed transactions within a microservices architecture - Red Hat Developer
The Microservices architecture will be a good choice if you prefer evolutionary, fault tolerance, modularity, scalability, deployability, elasticity characteristics rather than simplicity, performance, and overall cost.
These are just the tip of the iceberg. Even a book can be written on this topic alone. However, you should look at what has already been written such as; Building Microservices book by Sam Newman and Domain Driven Design book by Eric Evans.
If you want to see a real-world example, you should check our micro-service transformation below which is written by my colleague Cem Başaranoğlu.
As I mentioned in most of my article, there is no bad or good thing. Only trade-offs. You can find the right one for you by extracting the characteristics according to your domain and evaluating the advantages and disadvantages of each architecture.
Finally, don’t be afraid to make the wrong choice. Every wrong choice provides an experience for the right choices you will make in the future.
FROZEN CAVEMAN ANTI-PATTERN … Generally, this anti-pattern manifests in architects who have been burned in the past by a poor decision or unexpected occurrence, making them particularly cautious in the future. While risk assessment is important, it should be realistic as well. Understanding the difference between genuine versus perceived technical risk is part of the ongoing learning process for architects. Thinking like an architect requires overcoming these “frozen caveman” ideas and experiences, seeing other solutions, and asking more relevant questions. — Fundamentals of Software Architecture: An Engineering Approach
Thank you for your time, I hope you found it useful.
Subscribe to Newsletter
You can unsubscribe at any time.
comments